GPT Application Development and Reflections
2023年7月31日 · 4472 字
In the past few months, it seems like we are in the midst of an AI revolution. Besides the well-known OpenAI ChatGPT, many novel, interesting, and practical AI applications have emerged, and using these applications has indeed boosted my productivity.
However, there seems to be a lack of comprehensive resources on GPT application development and its pathways. Therefore, I decided to compile some of my experiences and thoughts into a series, hoping to help others.
This article mainly introduces thoughts on GPT-related application development. In April this year, while developing the open-source project ChatFiles, I learned about GPT-related technologies. Due to limited time and energy, I hadn't had the chance to organize these insights into an article until recently. With new ideas, I open-sourced another project, VectorHub, which is also based on GPT Prompt and Embeddings technology. This deepened my understanding of GPT and Embeddings, leading to this sharing.
Starting with Prompts
AI application development has attracted many developers recently. Besides the well-known ChatGPT, many valuable AI applications have emerged, such as AI-based translation applications like openai-translator and immersivetranslate, writing tools like Notion AI, and coding assistants like GitHub Copilot and GitHub Copilot Chat.
Some of these applications optimize existing experiences, like the GPT-based translator openai-translator, which offers superior translation quality and reading experience compared to previous machine translations. Others provide previously unattainable functionalities, like GitHub Copilot for code completion and generation, and GitHub Copilot Chat for answering coding-related questions, explaining code, generating unit tests, and suggesting fixes for erroneous code. These functionalities were unimaginable before.
Although these applications differ in functionality, they all primarily rely on GPT's Prompt (instructions). A Prompt is the text or instruction provided to the model to guide it in generating natural language output (Completion). It provides context to the model and is crucial for the output.
We know that GPT (Generative Pre-trained Transformer) is an inference model based on two stages: pre-training and fine-tuning.
In the pre-training stage, a large corpus is used for foundational training, such as Wikipedia, news articles, novels, etc. After training, when given a sentence, it predicts the next word based on the learned knowledge, generating a sequence of words through repeated predictions. This is why it's called a generative AI.
This sentence is what we call a Prompt, the foundation of generative AI's probabilistic generation. This explains why the same Prompt can yield different results each time, as each result is probabilistically generated.
Thus, we understand the importance of Prompts in GPT application development. Besides fine-tuning, it's our only way to interact with the GPT model (though we can also adjust the model's temperature and top_p settings to control the diversity or creativity of the output, but this doesn't significantly affect output quality or downstream task handling). Therefore, Prompts are the core of GPT application development and require developers' careful consideration and optimization.
After pre-training, in the fine-tuning stage, the GPT model is loaded onto specific tasks and trained with task-specific datasets. This allows the model to better understand Prompts and generate task-relevant text. Fine-tuning enables GPT to adapt to different tasks, such as text classification, sentiment analysis, Q&A systems, etc. However, due to high costs and unstable results, fine-tuning isn't a viable option for most GPT developers. Hence, most GPT application developers rely on Prompts for development.
Learning Path for Prompts
For basic knowledge of Prompts, you can start with Andrew Ng's ChatGPT Prompt Engineering. In less than two hours, you can quickly grasp the usage and charm of Prompts.
After gaining a preliminary understanding, I recommend the Prompt Engineering Guide. This document contains extensive foundational knowledge and future directions for Prompts. Besides learning the basics, GPT application developers can gain insights into the engineering and academic perspectives on Prompt development, which are invaluable for AI application development.
Lastly, I highly recommend checking out OpenAI's official GPT Best Practices. This document, provided by OpenAI, includes numerous Prompt examples and usage tips, making it a valuable resource for GPT application developers. It summarizes best practices from various business domains through partnerships and hackathons.
Best Practices for Writing Prompts
For best practices in writing Prompts, the most recommended resource is OpenAI's official GPT Best Practices. However, for GPT application development, I want to share some practices combining these best practices with my own experiences.
Clarity and Detail
In reality, most developers use GPT primarily to solve programming problems or ask questions, often bringing their experience with search engines like Google into using and developing GPT.
For example, if you want to know how to write a Fibonacci sequence in Python, you might type python fibonacci in Google. This is sufficient because Google, based on inverted indexing and PageRank algorithms, can provide high-quality web answers with just keywords.
This minimal input method is the simplest and most efficient. Even if you type a few more words like how to write python fibonacci, the output quality on Google doesn't differ much.
However, using GPT, an input like python fibonacci is unfriendly because it can't clearly understand your intent, possibly giving irrelevant results (varying slightly with different model qualities).
But if you input Write a Python function to efficiently calculate the Fibonacci sequence. Comment on each line of code to explain its purpose and why it's written that way, this is clear and detailed for GPT. It can understand your intent, providing more accurate results, ensuring a minimum quality threshold while improving the upper limit of output quality!
This differs from developers' experience with search engines like Google and is often overlooked by GPT developers and users. Early this year, while developing the ChatFiles project, I anonymously collected user Prompts and found that over 95% of users used very simple Prompts, sometimes as brief as a few words.
Therefore, when developing GPT applications, developers must ensure Prompts are clear and detailed. Try multiple times to choose a Prompt with stable output quality and consistent format, which is key to ensuring GPT application quality.
Handling More Complex Tasks
Most developers can design good Prompts and achieve decent output quality for simple tasks by spending some time adjusting Prompts. However, for complex tasks, improving GPT's output quality requires two crucial techniques: making GPT reason instead of answer, and breaking down tasks for guidance.
Reasoning Instead of Answering
Reasoning instead of answering means instructing the GPT model not to immediately judge correctness or provide an answer but to guide it into deeper thinking. You can ask it to list various views on the problem, break down the task, explain each step's reasoning, and then conclude. Adding step-by-step reasoning requirements in the Prompt makes the language model spend more time on logical thinking, resulting in more reliable and accurate outputs.
For example, if you need GPT to evaluate a student's solution, a Prompt like Evaluate if the student's solution is correct might lead to incorrect answers for complex problems because GPT doesn't reason like humans. It immediately judges, often leading to errors (similar to humans struggling with complex math in a short time).
But if the Prompt is First solve the problem yourself, then compare your solution with the student's and evaluate if the student's solution is correct. Do not determine the correctness of the student's solution before solving the problem yourself, this clear guidance makes the GPT model spend more time deriving the answer, resulting in more accurate outcomes.
Breaking Down Tasks
Breaking down tasks for guidance means splitting a complex task into multiple subtasks, guiding the GPT model through each, and then integrating the results. This approach helps the GPT model focus on each subtask, improving output quality.
For instance, summarizing a book directly might not yield good results. Instead, you can summarize each part through a series of subtasks and then compile the summaries.
However, breaking down tasks introduces new challenges, such as the quality of individual task outputs affecting the overall result. Additionally, with current token costs, breaking down tasks incurs extra costs. Nevertheless, designing and breaking down complex tasks is crucial for GPT applications, maintaining their competitive edge, and is a core design point for large model AI frameworks like LangChain. This topic deserves a separate article for discussion.
Usage Tips
Besides the important practices mentioned above, some small tips can be very helpful for application development. Here are some summarized tips:
- Provide a few examples (Few-Shot Prompting): Give the model one or two expected input-output examples to help it understand our requirements and expected output format.
- Request structured output in the Prompt: Output in JSON format for easier subsequent code processing.
- Separators: Use separators like
"""to isolate different instructions and contexts, preventing conflicts between system and user Prompts.
GPT Embedding Application Development
Above, we mainly discussed developing AI applications based on Prompts. However, sometimes we encounter new problems. For instance, large models' training data is often months or even years old. When we need GPT applications to provide the latest data, like answering questions based on recent news or private documents, the large model hasn't been trained on these materials and can't solve such problems.
In such cases, we can have the model use reference texts to answer questions. For example, our Prompt can be:
You will receive a document separated by triple quotes and a question.
Your task is to answer the question using the provided document and cite the text used to answer the question.
If the document does not contain the information needed to answer the question, simply write: "Insufficient information."
If providing an answer, include citation notes.
Use the following format to cite relevant paragraphs ({"citation": …}).
This approach allows GPT to answer questions based on the provided reference text. For example, if we want to know the latest World Cup champion, we can attach the latest World Cup news as a reference text. GPT will understand the entire news article before answering the question. This way, we can address the issues of timeliness and specific downstream tasks for large models.
However, this solution introduces another problem: the length limit of reference texts. GPT Prompts have size limits, like the gpt-3.5-turbo model, which has a 4K token limit (~3000 words). This means users can input a maximum of 3000 words for GPT to understand and infer answers.
If the required reference text exceeds 3000 words, we can't get an answer from GPT in one go. Developers need to split the reference text into multiple parts, convert them to GPT Embeddings, and store them in a vector database. For more information on vector databases, refer to my other blog Vector Database. When querying the reference text, convert the question to a vector, retrieve it from the vector database, and convert the retrieved vectors back to text. This way, we get reference text within GPT's token limit, relevant to the question.
We submit the question and the relevant reference text to GPT to get the desired answer. This process is the core of GPT Embeddings application development. The core idea is to retrieve the most relevant text segments through vector retrieval, bypassing GPT's token limit.
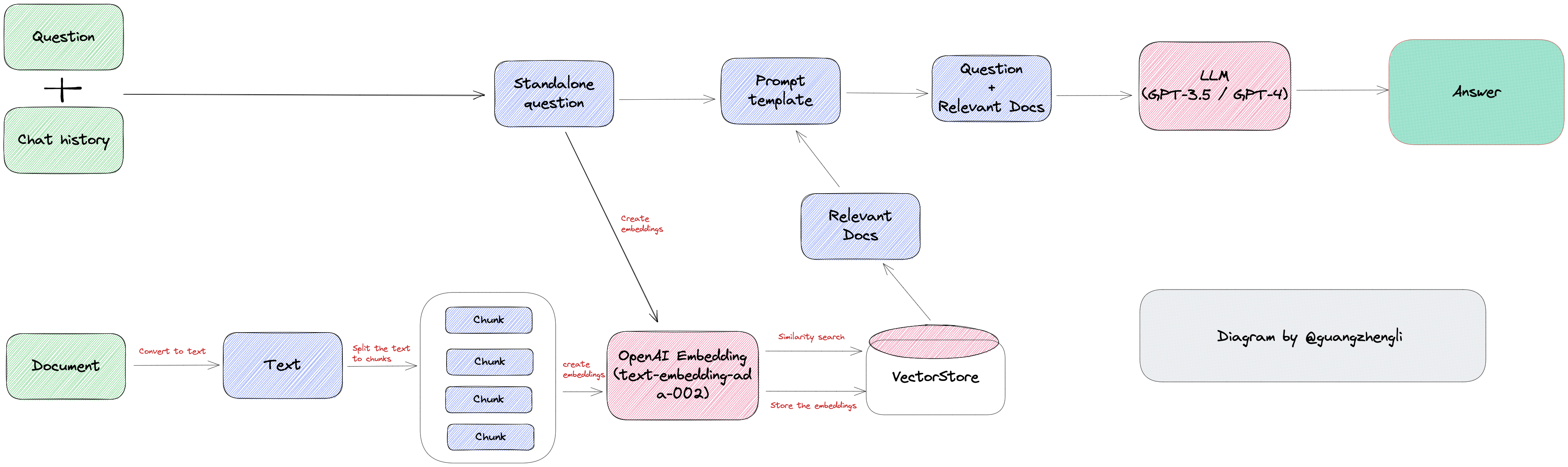
The overall development process is as shown in the image above:
- Load the document and obtain the target text information. For example, in the mainstream LLM framework LangChain, there are two text acquisition methods: File Loader and Web Loader.
- File Loader based on the file system, such as loading PDF files, Word files, etc.
- Web Loader based on the web, such as a webpage, AWS S3, etc.
- Split the target text into multiple paragraphs, mainly based on two methods.
- One is the text quantity-based splitting method, such as 1000 words per segment. This method is simple but may split a paragraph into multiple segments, reducing coherence and potentially lowering answer quality due to missing context.
- The other is the punctuation-based splitting method, such as using line breaks as separators. This method maintains coherence but results in varying segment sizes, potentially triggering GPT's token limit.
- The last method is the GPT token limit-based splitting method, such as grouping 2000 tokens and searching for the two most relevant segments during the query. This way, the combined segments stay within the 4096 token limit.
- Store the split text blocks uniformly in the vector database.
- Convert the user's question to a vector, retrieve the most relevant text segments from the vector database (note that this retrieval is not traditional database fuzzy matching or inverted indexing but semantic search, so the retrieved text can answer the user's question. For details, see another blog Vector Database).
- Combine the retrieved relevant text information, user question, and system Prompt into a Prompt for the Embeddings scenario, clearly stating to answer the question using the reference text, not GPT itself.
- GPT answers the final Prompt, providing the desired answer.
If you're interested in the specific implementation code, check out the Retrieval chapter in LangChain.
GPT Embeddings applications can solve problems that GPT alone can't answer, which is their biggest advantage. Without training or fine-tuning, simply converting text to vectors and retrieving them can make certain business scenarios possible at a low cost.
However, this solution also introduces new problems, such as the quality of text splitting and retrieval significantly affecting the final result. Balancing query range, quality, and time, and handling cases where the retrieved reference text can't answer the user's question are all issues developers need to carefully consider for business needs and scenarios.
Looking further ahead, all documents in human history have been written for humans, not optimized for vector retrieval. Will there be texts specifically written for AI and retrieval in the future, making AI better understand and align with database retrieval? These questions require long-term thinking and validation, which we won't expand on here.
GPT Agents Application Development
Beyond the business needs that can be addressed by the aforementioned prompt and embeddings solutions, there is another very common requirement in GPT application development: how to integrate with existing systems or APIs.
The software industry has been evolving for many years, and many companies have their own systems and APIs. These APIs can significantly extend the capabilities of GPT applications. If a GPT application is to be implemented in real-life scenarios, it inevitably needs to integrate with existing systems.
For instance, if you want to ask GPT a simple question like, "What's the weather in Beijing today?" From the previous sections, we know that GPT cannot answer such questions on its own. However, if GPT can call a weather API, development becomes much more convenient.
To achieve the requirement of GPT calling a weather API, we face two problems: one is to make the GPT application understand the function of a particular API and call it when appropriate; the other is that the input and output must be structured to ensure system stability.
Understanding and Calling Existing APIs
To make GPT understand the function of an API, the best way is for developers to manually add names and specific descriptions to the API, including the structure of input and output values and what each field represents. This can greatly influence GPT's judgment and ultimately decide whether to call the API.
For example, the description of calling a weather API on the OpenAI official website is as follows:
function_descriptions = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {
"type": "string",
"description": "The temperature unit to use. Infer this from the users location.",
"enum": ["celsius", "fahrenheit"]
},
},
"required": ["location"],
},
}
]
The above method describes in detail that to call this function, at least the current location information must be provided, and the temperature unit can be optionally provided. GPT will decide whether to call this function based on whether the question is related to the function's description. The specific code details can be written in another article, so we won't expand on it here.
By providing a large number of API documentation, we can help LLMs understand and learn the functions, usage, and combination methods of these APIs. Ultimately, this allows the overall requirements to be broken down into multiple sub-tasks, with each sub-task interacting with a specific API, achieving automation and AI goals.
The existing APIs we describe here are not limited to HTTP requests. They can include converting to SQL queries to databases, calling SDKs to achieve complex functions, and even in the future, extending to calling physical world switches, robotic arms, etc. Personally, I believe that based on the current capabilities and development trends of GPT, the way humans interact with machines will undergo significant changes.
Structured Output
In addition to making GPT understand and call existing APIs, we also need to ensure that the results output by GPT can be understood by existing systems. This requires the output to be structured, such as data in JSON format.
You might immediately think, can't we achieve this through prompts? In most cases, yes, but in some rare cases, prompts are not as stable as function calling. Traditional systems have very high requirements for stability. For example:
student_description=Wang is a sophomore majoring in computer science at Peking University, with a GPA of 3.8. He is very skilled in programming and an active member of the university's robotics club. He hopes to pursue a career in artificial intelligence after graduation.
In this passage, we can use a prompt to require the output to be in JSON format, such as:
Please extract the following information from the given text and return it as a JSON object:
name
major
school
grades
club
This is the body of text to extract the information from:
{student_1_description}
However, the difficult part is that we cannot ensure whether GPT will output 3.8 or 3.8 GPA for grades. For humans, there is no difference between these two outputs, but for computers, they are completely different. The former is a floating-point number, and the latter is a string. For some languages, conversion will directly result in an error.
We can certainly reduce such problems by adding more descriptions to the prompt, but the reality is more complex. It is difficult to fully describe the requirements through natural language, and it is hard to ensure that GPT's answers will always maintain the same output. Therefore, for such problems, using the function calling method provided by OpenAI can solve the interaction problem between natural language and machine language to a certain extent.
For example, the above problem can be described as a function, where we describe the grades field as an integer to avoid such issues. This structured capability is crucial for developing a stable system.
student_custom_functions = [
{
'name': 'extract_student_info',
'description': 'Get the student information from the body of the input text',
'parameters': {
'type': 'object',
'properties': {
'name': {
'type': 'string',
'description': 'Name of the person'
},
'major': {
'type': 'string',
'description': 'Major subject.'
},
'school': {
'type': 'string',
'description': 'The university name.'
},
'grades': {
'type': 'integer',
'description': 'GPA of the student.'
},
'club': {
'type': 'string',
'description': 'School club for extracurricular activities. '
}
}
}
}
]
For the complete debugging process, you can check out this OpenAI function calling example.
GPT Application Requirements Analysis
The above mainly discusses some techniques for developing GPT applications, but if we want to create a product, we still need to start from business needs and think about what kind of business value we can create to meet the current potential users' needs.
Update on 2023/09/06: The official LangChain documentation has been updated, dividing the documentation into RAG (Retrieval Augmented Generation) and Agents sections. This indicates that since the explosion of GPT a few months ago, the industry currently believes that RAG and Agents are the two directions for business needs to land. RAG is mainly the GPT Embeddings part we discussed above, and we will also give examples from these two directions later. I think anchoring to leading frameworks like LangChain is very valuable for developers because they summarize some best practices and experiences in the process of business implementation, which is very helpful for developers to understand business needs.
Content Generation
Content generation is currently the most mainstream demand and the direction with the highest traffic statistics in current AI applications. Besides well-known products like ChatGPT, there are also high-traffic AI companion (role-playing) applications like Character AI mainly developed based on prompts.
In the broader content generation category, there are image generation fields like Midjourney, voice generation fields like ElevenLabs, text creativity fields like copy ai, and some niche text content generation fields like novel generation assistance AI-Novel, etc.
Content generation is currently the AI demand field with the highest internet traffic and the easiest to implement because its application scenarios are very broad. Content generation assistance can often directly improve productivity, so the willingness to pay is often not low. The competition in this field is often the most intense.
GPT Embeddings Demand
GPT Embeddings is a direction I think has great potential value. When ChatFiles was just open-sourced, I received some inquiries asking if it could optimize existing scenarios and businesses in customer service, sales, operation manuals, knowledge bases, etc. My personal answer is that GPT Embeddings has great prospects in these scenarios.
In this field, we can currently see startups like mendable ai that have already occupied a certain market share, supporting document Q&A functions for leading GPT frameworks like LangChain. They are also actively expanding business scenarios such as sales and customer service.
In addition, the website with the highest traffic in this field is currently ChatPDF, where you can upload PDF files and then ask questions and make requests based on the PDF, such as summarizing. This direction has also derived various niche demands, such as assisting in reading and collaborating on papers like Jenni AI.
GPT Agents Demand
The demand for GPT Agents is diverse because it is based on the integration of existing systems. By analyzing the APIs of existing systems, we can determine what kind of business value we can create. For example, many GPT-provided networking functions are achieved by integrating SerpAPI, which is an aggregated query website that integrates major search engines. This allows ChatGPT to answer some search-based questions, such as current weather, stock market, news, etc.
Among them, the most famous are naturally the two projects Auto GPT and AgentGPT. If you are interested in GPT Agents applications, you might want to check out these two projects. In addition, companies like cal.com that integrate AI agents to enhance functions like scheduling meetings with natural language might give you some different inspirations.
Unstructured Input and Structured Output
Another point that I think many people overlook is the ability of GPT/LLM to handle unstructured data. In the past, we needed to spend a lot of development time to process some simple texts, such as extracting some key information from SMS, like names, phone numbers, addresses, etc. Due to different SMS templates, this information is unstructured.
We cannot convert this content into structured output like JSON format through a simple method, so we often need a set of complex regular expressions or NLP technology to extract this information. However, regular expression development is complex, and for different SMS templates, plus the templates change over time, we need to constantly adjust the regular expressions, which is a very time-consuming process for developers and engineers.
NLP technology can only be applied to certain specific scenarios, such as extracting phone numbers, extracting addresses, etc. For different scenarios, we need different NLP technologies. So once the business needs change, such as recognizing license plates, we need to redevelop and adjust.
But with a unified API like OpenAI GPT, we only need to provide different prompts to the service, and we can guide GPT to reason through the prompts to get the results we want. This can greatly simplify our development process, shorten development time, and quickly respond to market changes.
And due to GPT's strong generalization ability, we only need to think about how to handle unstructured data for different scenarios. This ability to handle unstructured data will change many traditional business development processes and methods in future software development, having a profound impact on the software lifecycle.
Natural Language Interaction
Finally, I want to say that GPT's ability to handle natural language will deeply change the way humans interact with machines. In the past, from command lines to graphical interfaces, to touch screens, these are all histories of human-machine interaction revolutions. Most people's interaction with machines actually requires the programmer as a medium. People have various needs, business analysts and developers extract the needs, and programmers generate graphical pages through code. People then interact with the graphical pages to achieve human-machine interaction.
This process involves information transmission loss and generates a lot of limitations and costs. If machines can understand natural language, we can interact directly with machines. Then the concepts of software, machines, and intelligence that we are familiar with will undergo tremendous changes, and human-machine interaction will also undergo earth-shaking changes.
If you find it hard to understand this uncertain, unreferenced change, you can experience the open interpreter project. It is a project that generates code based on natural language and executes it directly on the computer. Although it is very primitive and unstable, you can see the revolution in human-machine interaction from it.
References
- https://github.com/guangzhengli/ChatFiles
- https://github.com/guangzhengli/vectorhub
- https://js.langchain.com/docs/modules/data_connection
- https://www.datacamp.com/tutorial/open-ai-function-calling-tutorial
- https://openai.com/blog/function-calling-and-other-api-updates
- https://openai.com/blog/chatgpt-plugins#code-interpreter
- https://github.com/KillianLucas/open-interpreter
- https://www.chatpdf.com
- https://jenni.ai
- https://github.com/reworkd/AgentGPT
- https://a16z.com/how-are-consumers-using-generative-ai