谈谈 AI 编程工具的进化与 Vibe Coding
2025年8月28日
最近关于 AI 辅助编程和 Vibe Coding 的讨论非常激烈,想了想还是写一篇博客来表达我自己的观点。
我是从 2023 年开始使用 GitHub Copilot 的, 2024 年的时候开始持续使用 Cursor,并于几个月前开始开始大量使用 Claude Code。
虽然没有时间去体验市面上所有的 AI IDE,但我想这三个产品对于 AI 辅助编程而言还是有里程碑式意义的,也可以说我是积累了一些经验来谈一谈 Vibe Coding 的。
Vibe Coding 并不是一个好名字
Vibe Coding (中文翻译为氛围编程)这个名字从籍籍无名到每个程序员都在谈论,应该是从 Andrej Karpathy(前特斯拉人工智能总监,OpenAI 的创始成员之一)的这条推特开始的。
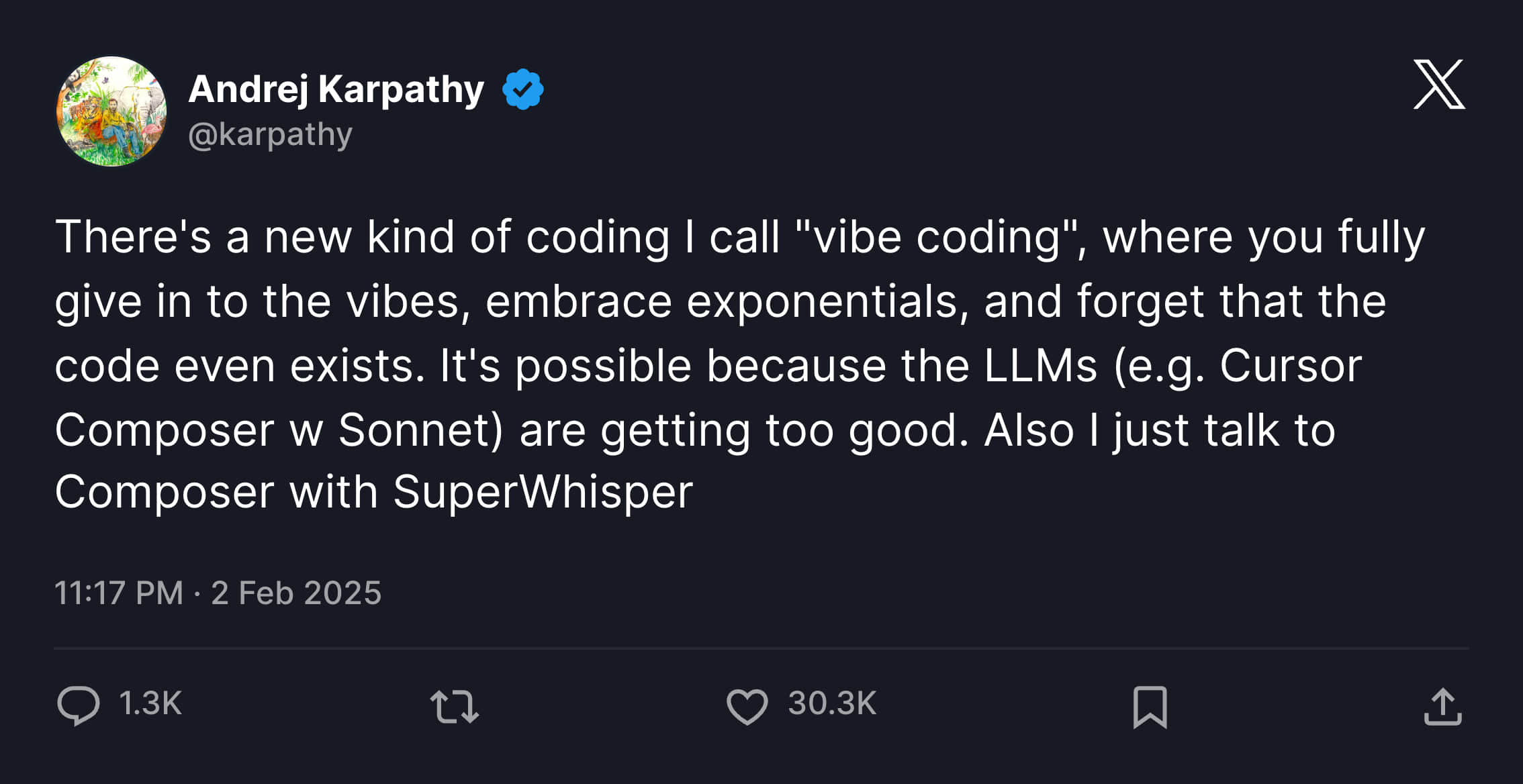
我把原文贴在下面:
There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard. I ask for the dumbest things like "decrease the padding on the sidebar by half" because I'm too lazy to find it. I "Accept All" always, I don't read the diffs anymore. When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I'd have to really read through it for a while. Sometimes the LLMs can't fix a bug so I just work around it or ask for random changes until it goes away. It's not too bad for throwaway weekend projects, but still quite amusing. I'm building a project or webapp, but it's not really coding - I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.
我个人一般是不喜欢咬文嚼字的,但是基于 vibe coding 现在成为了一个万能的词,目前所有通过 AI 来辅助和编写代码的工具和方式都统一被称为 vibe coding 的现状,我觉得还是有必要来区分一下的。
基于原文的内容,Andrej Karpathy 对于 vibe coding 的定义我认为有几个关键点:
- forget the code even exists -> 忘记有代码的存在。
- 几乎不手动参与编程,再小的错误也通过 AI 来修复而不是手动更改。
- AI 写的代码不再 review,只看结果,不满意的话继续对话。
- 对于一次性的项目来说,并不糟糕,并且相当有趣。
所以 vibe coding 的意思我理解从最开始是谈论一个新的编程方式,是一种完全基于 LLM 对话来编程的方式。
可能是因为 vibe coding 不好翻译或者没有明确意义的原因,目前确实发展到只要是通过 AI 工具来辅助编程,或者是通过 AI 来编写代码的方式,都统一称为 Vibe Coding 了。
我认为目前很多的讨论和争论的原因,都是没有区分这两种方式。
可能一种叫做 vibe coding,另外一种不管是叫 AI 辅助编程,AI Coding、Agents Coding 还是 Context Coding 都会更好一点。
虽然这两种编程方式的本质不同,但是我还是想在谈论 vibe coding 之前,先来谈论一下基础的 AI 辅助编程方式。
Context Coding
我个人更愿意把基于 AI 辅助编程的方式称之为 Context Coding。基于上下文编程,或者是上下文驱动编程。
原因是我个人认为 AI 编程的进步,除了最重要的大模型的编程能力变强之外,例如模型从 GPT 升级到 Claude,还有一个重大的提升,不同 AI 编程工具的上下文工程(Context Engineering)能力更强了。
被大家广泛讨论的最强 AI 编程工具,基本上是从 GitHub Copilot 到 Cursor,再到 Claude Code,我认为这些产品成功的原因是上下文工程(Context Engineering)更加科学了。
在大模型不变的情况下,AI 辅助编程的所有提升都是基于给 LLM(大语言模型) 传递更合适的上下文这个基本原理展开的,无论是 Chat, RAG, Rules, MCP 还是未来更酷的一些其它技术。
所以我们以给 LLM 提供合适的上下文这个视角出发,先来剖析一下这些产品的特性,从中学习如何更好的使用 AI 来辅助编程。
GitHub Copilot
相信大部分人最开始接触的 AI 辅助编程工具都是从 GitHub Copilot 开始的,除了集成 AI 对话功能外,给我印象最深刻的莫过于代码补全功能。
在这之前,VSCode 一直被诟病的是代码补全能力不如 IntelliJ IDEA, IDEA 通过构建完整的代码索引,AST(抽象语法树) 和智能排序算法来实现代码补全功能,过去十几年一直广受程序员喜爱,一直是我最喜欢用的 IDE。
无论是什么语言的项目,我在这之前都无脑选择 IDEA 来编程,直到 VSCode Copilot 的出现,我开始在 VSCode 和 IDEA 来回切换,直到后来完全抛弃了 IDEA。
GitHub Copilot 最开始的成功在于,它是第一个将代码上下文共享给 LLM 的集大成者,主要体现在两个能力上:
第一个是可以将当前 IDE 打开窗口的代码提供给 LLM,并且可以针对当前窗口的代码进行提问并给出建议。
这在当时(2023年)是一个非常大的惊喜,因为当时大多数人都是将代码复制到 ChatGPT 中,然后从 ChatGPT 中复制代码到 IDE 中。
第二个是可以根据当前代码文件的上下文进行补全操作,Copilot 将光标所在位置的代码上下文提供给了 LLM,LLM 据此给出了建议。
这个功能出现后,我的编程习惯发生了第一个重大改变,就是喜欢先写方法注释,让 Copilot 基于注释生成对应的方法,然后我再去修改方法的一些细节,这个模式大大加快了一些编码的速度。
但是在当时 Copilot 的缺点也非常明显,首先是模型能力不够,GPT 3.5 虽然非常惊艳,但是在编程方面还是幻觉太大了,并且能够接受的上下文非常有限,所以在当时,实际全量接受 LLM 给出的建议和代码补全的概率非常有限。并且当时 Copilot+ GPT 3.5 还没有能够直接编辑代码的能力,需要手动从 LLM 给出的建议中复制代码。
还有一个是当时 Copilot 只能把当前打开的窗口的代码文件的上下文给到 LLM,所以 LLM 无法根据其它文件或者整个项目的上下文给出建议。
导致有时候你在一个代码文件中实现了一个方法,切换到另一个文件时,LLM 并没有那个方法文件的上下文,无法给出基于那个方法的调用补全。更别说如果一个编程任务要跨越几个文件进行共同检索和修改的话,在当时是无法想象的。
所以在这种情况下,提供更好上下文的 Cursor 就脱颖而出了。
Cursor
在 Copilot 出现后,市场上出现了大量的 IDE 插件形式 AI 辅助工具,区别只是在 promot 和 LLM 上优化而已。直到 Cursor 这种以完整 AI IDE 形式的工具出现,AI 插件辅助编程的竞争才告一段落。
我们先来聊聊和上下文工程无关的技术提升,第一是 Cursor 针对 Tab 自动补全能力设计了专有模型,给我最深的印象是速度非常快,并且非常精准,接受代码补全的概率相当高,当时有戏称程序员从 Copy 工程师变为了 Tab 工程师。
第二是当时 Claude 3.5 Sonnet 模型的出现,比 GPT 模型拥有能强大的编程能力,加上上下文长度增加和直接编辑文件能力。
可以说当时 Cursor Tab 模型加上 Claude 3.5 Sonnet 模型两个能力的叠加,从此让 AI 辅助编程从"代码补全工具"进化为了"编程智能体"。
除此之外,Cursor 的上下文工程也非常值得我们学习。
Cursor 在上下文工程的第一个关键突破就是使用 RAG(Retrieval Augmented Generation) 将项目整个 codebase 进行索引,并以语义(向量)搜索的方式给 LLM 提供整个项目的上下文。
如果你注意过的话,就会发现使用 Cursor 打开一个新的项目,在 Cursor Settings 的 Indexing 的设置中,Cursor 会开始索引你的整个项目,并且你可以看到目前索引了多少文件。
这背后的原理,我们简单的介绍一下,Cursor 会在你新打开项目的时候,将整个代码库在本地拆分为多个小块内容,然后再上传到 Cursor 云服务器中,使用 embedding 模型来 embeds 代码,并存储到云向量数据库中。
接着你在 Chat/Agent 中提问时,Cursor 会在推理时对 prompt 进行嵌入,让 Turbopuffer 进行最近邻搜索,将混淆后的文件路径和行范围发送回 Cursor 客户端,并在客户端本地读取这些文件代码块。
Turbopuffer 是基于对象存储从头构建的无服务器向量和全文搜索,如果你不太清楚向量搜索,你可以简单理解为语义搜索,可以搜索出意思相近的词。
如果你想要对 embedding 和向量数据库有更多了解。可以查看我 2023 年的博客 GPT 应用开发和思考 和 向量数据库。
基于这种能力,Cursor 可以检索出和你当前对话相关的代码上下文,并一同提供给 LLM。这样 LLM 有了多个文件的上下文后,可以做到:
- 实现跨文件的方法调用
- 修复涉及多个文件的bug
- 重构整个模块
- 添加需要修改多处文件代码的新功能
在这个基础上,Cursor 也支持直接 @ 某个文件/文件夹来给 LLM 提供上下文,并且在后续加上了索引 Git 历史记录的能力。
从上下文工程的角度来讲,可以说 Cursor 比 Copilot 成功的地方在于,Cursor 给 LLM 提供了更全面的代码上下文,并且给了用户更自主控制上下文的能力。
除此之外,Cursor 在后续添加了文档的索引功能,可以帮助你给 LLM 提供最新的技术文档上下文。并且添加了 Rules 相关的功能,可以给 LLM 提供通用的编程规则,确保 LLM 生成的代码与你的项目架构、编码风格和技术栈保持一致。
这些功能无一例外都是为了给 LLM 提供更丰富、更合适的上下文而展开的,所以我更愿意称它为 Context Coding。
Claude Code
在 Cursor 以各种优化上下文工程保持领先状态时,Claude Code 以一种完全意想不到的方式杀入了比赛。在 Claude Code 这个产品出现以前,我是完全没有料想到终端命令行 CLI 这种方式也可以进行 LLM 辅助编码的。
虽然之前没有体验过终端命令行这种 AI 产品的形态,最开始产品发布的时候,我只是被 Unix 风格吸引,想要尝试一下。但是实际使用下来非常容易上手,并且编程效果不输给 Cursor,甚至部分情况下实际效果还要超越 Cursor。
实际测试编写 Next.js 程序,在中小型编程任务中,Claude Code 的效果和 Cursor 差不多,毕竟我两个工具通常情况下都是使用 Claude 4 sonnet 或者 Opus 模型,Cursor 在实际编程体验上还是要更便捷一点,因为还是会使用 command + K 或者 Tap 补全。
但在大型编程任务中,例如一次要检索修改超过 10 个文件的情况下,Claude Code 的编程效果远超 Curosr。我认为根本原因在于 Claude Code 给 LLM 提供上下文是量大管饱的策略。
Cursor 因为是大模型基座提供商(例如 Claude)的下游产品,如果想要在商业领域取得成功,那么就需要在用户付费和实际 Tokens 的使用上取得平衡。所以有了很多引起程序员不满的调整模型速度、使用次数限制、自动引入低能力模型的各种骚操作。
我长期使用下来也是很想吐槽,随意调整使用次数限制也就算了,一不注意就把模型自动调整到 Auto 这种低端模型,而且把 IP 切换到美区住宅,和 CN/HK 对比时模型能力和速度有时候会有巨大的差异。
总之在 Cursor 这种商业平衡之下,加上外部竞争不大的阶段,实际的体验可以说是缩水了不少。
与 Cursor 不同的是,Claude Code 由于本身是大语言模型基座提供商 Anthropic 的产品,在消耗 tokens 这件事上并没有那么畏手畏脚。
Claude Code 每次一上来就先通过终端命令开始分析代码库的项目结构和基本的技术栈信息,这与 Cursor 关注点在具体的任务和少数的代码文件中不同,Claude Code 以一种更全局的视角先分析项目整体情况,然后再开始开发。虽然这肯定是更加消耗 tokens ,但是有了这些项目整体信息后,Claude Code 编写的代码确实更加符合项目原本的开发模式和编码规范。
加上 Claude Code 选择了一套和 Cursor 完全不同的检索代码上下文的方案,那就是基于 Unix 工具的检索方案。 例如使用 grep, find, git, cat 等等终端命令而不是 RAG 的方案。
这种方案一般来讲更加符合程序员的编程习惯,例如程序员在做某个编程任务时,如果不熟悉代码,一般会从某个关键方法名或者对象名称开始,一层一层的开始模糊搜索或者正则搜索。直到找全了业务相关的代码,再开始编程。
Claude Code 选择的就是这种上下文工程模式,在你提问之后,基于你的提问进行关键词不断检索,直到找到项目中所有需要的上下文代码,然后再开始编程,亦或者是一轮一轮的对话、编程和检索,一直重复这个过程,直到 LLM 认为找全了上下文。
Claude Code 选择这个和 Curosr RAG 不同的方案后,社区中有大量的争议出现。
RAG 一派认为 grep 方案的召回率低,检索出大量不相关的内容,不仅费 token,并且效率慢,因为 LLM 需要不断对话和不断检索新的上下文。
grep 一派则认为复杂的编程任务需要精准的上下文,而 RAG 的方案在代码检索的精度上,表现的并不佳,毕竟代码的语义相似度不等于代码关联的上下文,更不等于业务上下文。
并且像 Cursor 这种基于文件哈希值的 Merkle 树的索引更新同步的方案,在大量重构代码时,或者是索引服务器负载时,检索出来的是过时的代码,提供过时的上下文。
这两派的说法其实都是有道理的,Claude Code 在速度和 tokens 消耗上不如 RAG 方案,Cursor 在复杂任务下表现不如 Claude Code,体验下来我觉得也是事实。
但结合来看我觉得在大语言模型能力没有溢出的时代,可以先不考虑速度和 token 消耗的事情,毕竟最终能否解决某个工程问题才是当前最重要的事情,也是所有 AI 编程工具的第一目标。从这一方面来看,Claude Code 更符合选择。
当然,并不是说我完全同意 grep 的方案,我觉得在未来一段时间内,完整的 AI IDE 一定会提供 RAG + Grep 两种能力,在不同的情况下选择性使用,像 Cursor 一定会在 grep 方案上发力,而不是全依靠 RAG 的方案。
但像 Claude Code,Gemini CLI 之类的我觉得是没有必要参考 Curosr,集成 RAG 之类的方案的,因为可能有人没有意识到的是,Claude Code 的发力方向除了辅助编程之外,还可以直接通过可脚本化的工作流与所有的开发环境协作。通过 bash 环境集成代码库、MCP 市场以及用于 CI/CD 自动化的 DevOps 工作流中。
这些环境完全适应目前的 grep 等检索方案,完全没有必要为了 RAG 而穿上裹脚布。Claude Code 之类的产品在上述的领域想象空间很大,也是 AI 产品蓝海市场。
如何更好的 Context Coding
那我们学习了这么多的 AI 产品的上下文工程,是否能够帮助我们更好的 Context Coding 呢?我觉得还是有不少借鉴意义的。
既然 AI 辅助 Coding 的关键在于给 LLM(大语言模型) 传递更合适的上下文,那么有时候借鉴我们自己日常的开发思路其实能够更好的帮助我们理解:如何给 LLM 传递更好的上下文。
假如你需要进入一个新的项目组,你只有这个项目需要的技术和框架基础知识(LLM 也只有技术和框架基础)。
那么通常来讲你将代码库 clone 后,第一件事一般是先了解项目的技术栈有哪些,然后浏览代码库的目录结构,并试图理解大致的项目目录结构和分层,尝试了解每个类型的命名文件是干什么的。这些流程对我们日常了解一个新项目都非常有帮助。
所以我们给 LLM 提供的上下文,最好也包含代码库的大致技术栈(用了哪些技术栈和工具),目录结构(项目结构和分层)和对应的文件是做什么的(文件命名及其含义)。
因为 LLM 默认每一个新的 session 都没有以往的记忆,缺少上述这些上下文,所以我们也最好将这些信息存到指令文件,或者叫规则文件中,例如 GitHub Copilot 的 .github/copilot-instructions.md 文件,Cursor 对应的 .rulers 文件夹和 Claude Code 的 CLAUDE.md 文件。
现阶段每个 AI Agent 都使用不同的规则文件命名,没有统一。所以如果你团队中同时使用多个 AI Agent,或者像我一样同时使用 Cursor / Claude Code 等工具,可以考虑采用 Ruler 这个开源项目来统一管理指令文件。
有了上述信息后,LLM 每次新的对话都能获取整体项目的基本上下文的信息再编程,这和我们一般先看这些信息,然后再去开发需求的习惯一致。
从这个角度出发,我们还能联想到更多项目基础上下文,例如常规开发时,除了我们了解上述的上下文之外,还会去看这个新项目的常用命令,例如 install packages, lint, test, build 等命令。包括还会去找工具类,查看有哪些公共的方法,新项目的核心业务模块,核心方法和核心文件分别在哪里,都是干什么的。有了这些信息我们才能进行更好的进行编程开发。
所以既然上述的信息对我们开发一个不熟悉的项目非常有帮助,那么理论上来讲它对于 LLM 大模型(可以简单理解为只有技术基础能力的实习生) 也就非常有帮助。
需要注意的是,这类上下文不是越多越好,特别是容易过时的上下文信息,例如文件目录、容易被重构的文件和工具类,一旦这些信息发生了改变,但是却没有同步到指令规则文件中,带来的危害比不提供这些上下文更大。这类文件如何维护更新是一个难题,特别对于大型团队项目来讲。
除了上述这些基础信息之外,你还可以要求 LLM 像一个有经验的程序员一样思考和开发,例如对待简单的任务,可以直接进行开发,对于困难的需求,可以先将需求进行拆分多个子任务,记录或者写到一个文档中,每个子任务完成后都更新状态到这个文档中,每一个子任务都进行小步提交,最后删除这个文档文件。
这个流程可以显著降低复杂任务下 LLM 的幻觉问题,我观察到 Claude Code 的 Coding 开发流程基本都使用这一套模式,实现上可能有些差别。
当然,像这一类成熟的开发思路和编程规范我们可以联想到更多:
- 渐进式的修改,小步提交
- 从现有的代码学习,找到2-3个类似的实现,尽可能使用相同的库/工具
- 代码让人看得懂比显摆技巧更重要
- 一个函数只解决一个问题,如果需要解释,那就太复杂了
- 没有充分理由,就不要引入新的工具
根据你的项目要求,和团队需要的编程规范,选择性的加入一些思路和规范到你的团队项目指令规则文件中,对 LLM 来讲也是非常有用的上下文。
当然,即使你将现在所有的编程规范和代码整洁之道加入到规则文件中,目前 LLM 也不太可能每次都写出抽象层次和健壮性足够好的代码,就我个人经验而言,想要 LLM 写好抽象还是太难了,可能用来训练的代码就没有太多写好抽象的代码吧。
除了项目基础信息和编程规范外,开发常用的工具和调试技巧对于 LLM 来讲也是好的上下文来源。
例如我们在日常开发中,如果需要调用某个第三方库或者最新的方法/API,最常见的就是访问他们的官方文档,然后查询最新的方法名字/API 路径等。对于 LLM 来讲也一样,训练的数据会过时,所以最好传入最新的文档给 LLM,我们可以通过 context7 等 MCP 来解决这个问题。
调试问题也是一样,你可以让 LLM 在有问题的代码的每一个角落都打上日志,模仿 IDE 的 debug 模式,这样可以让 LLM 获得足够多的调试信息输入,就像我们在 debug 模式中看到每一个方法的入参出参等一样。当然你也可以通过 MCP 等方式获取浏览器控制台日志、网络搜索回答等方式获取足够好的上下文给到 LLM。
讲到这里,相信大家也能明白,我举得这些例子,并不是想要说明上面的这些指令和规则文件是银弹,是能解决所有 AI 辅助编程的规则和指令。
而是想要表明,既然 AI 辅助编程的核心在于传递合适的上下文,那么我们在 LLM 效果不佳的时候,不如从我们常见和熟悉的开发思路和编程习惯入手,去思考如何传递更好的上下文给到 LLM。无论这个方式是 Rules,还是 MCP,一切围绕上下文工程这个目标展开。
像 Claude Code 这类的行业巨头,最近就内置了 /context 命令,可以非常直观的看到已经使用的上下文里面,不同类型工具的占比,包括还有多少剩余的上下文。
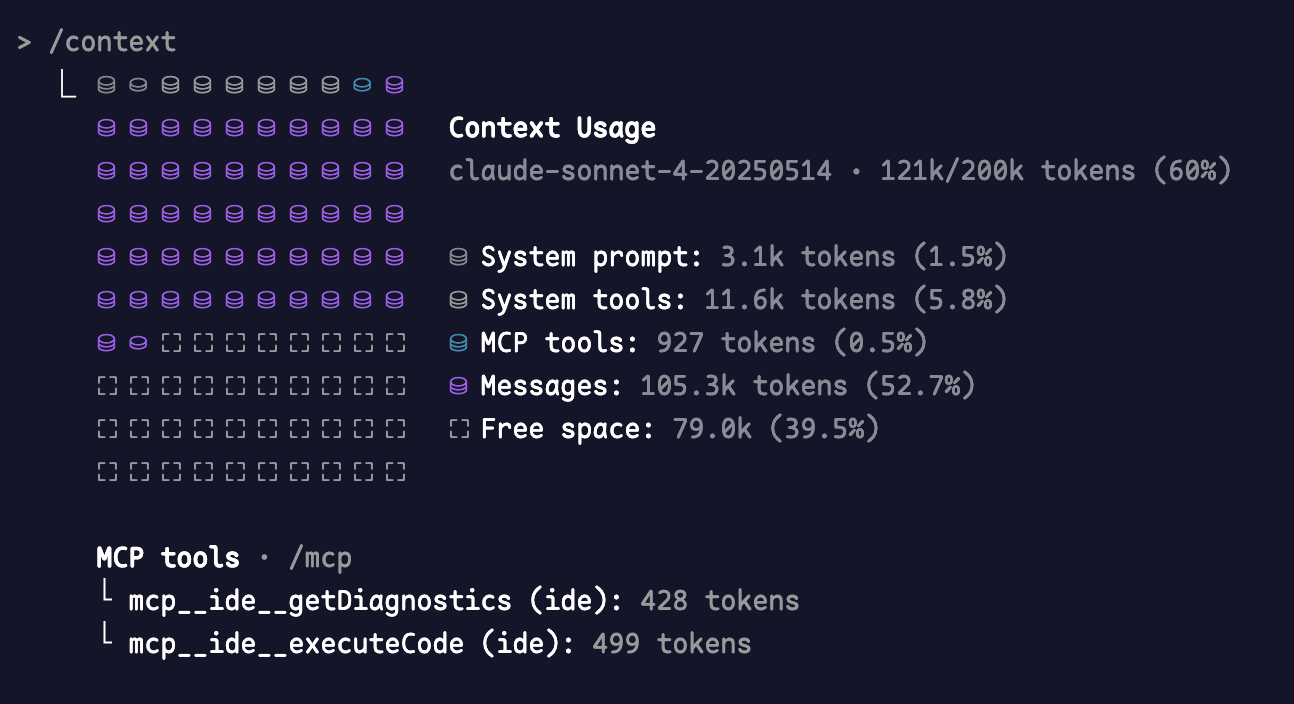
其实从这也能看出 Claude 团队对 Context Engineering 有深刻的理解,站在开发的角度来思考编程时应该如何管理上下文。
帮助你使用 LLM 的时候知道还剩余了多少 token,是否会随时触发压缩过程?是否需要提前压缩上下文?哪些提示词的 token 占比较大,可以帮助你了解和清楚 token 占用情况,例如是否有无效的 MCP 和工具占比过大的时候。
这应该是我见过第一个将 context 使用情况暴露给用户的 AI 工具,也是在上下文工程领域观察到不断进步的一个 AI 工具。
LLM 的提升和上下文工程之间的关系,就像之前内存硬件的提升和软件的内存控制管理不冲突一样,在 LLM 大模型和上下文容量都不容易提升的时候,谁提供的上下文更好,谁的上下文工程做的更好,更容易脱颖而出。这与 AI 编程无关,任何 AI 产品都如此。
个人看法
除了上面提到的 context coding 的一些技巧和经验,我也分享一些个人看法。
上面提到的 AI 编程工具没有哪个是能解决所有编程问题的,不是说 Claude Code 效果更好,Cursor 就没有存在的必要。
实际上在严肃的工程实践中,Cursor 的 Tab 代码补全反而是我用的比较多的存在,一个原因是因为我之前说过的 LLM 在抽象等问题上能力有限,不是过多的抽象,就是错误的理解我的意图,做一些不想要的东西出来。
例如创作 NextDevKit 模版的时候,因为模版的代码更需要健壮整洁,还有合理的模块抽象和分层,所以靠 LLM 来实现,完全没有办法提高效率。
这种情况反而通过 Tab 能提高不少的效率,例如自己写好分层和抽象,然后写注释和方法名,用疯狂的 Tab 代码补全来高效的生成代码,这种方式有时候比来回调整对话,直接让 LLM 输出全量代码要高效的多。
当然 Tab 有时候也很烦人,极端点比如我写这篇博客的时候,根本没有办法输出我想要表达的内容,只能通过快捷键来关闭它。
Claude Code 对于了解一些我不熟悉的新项目非常有帮助,例如我现在熟悉新项目和代码库,已经习惯性的让 Claude Code 来帮我输出整体项目的信息和情况。帮我分析要做的任务需要修改哪些地方,完成一些我不熟悉的技术栈的任务,在合理的编程规范引导下,比我自己上确实要强。
总而言之,好的工程师总是可以选择合适的工具来解决问题,而不是某个工具的信徒,不需要用工具来证明自己的价值。
除此之外,LLM 也改变了我的一些原有的编程习惯,例如原来我喜欢研究 IDE 的一些奇淫巧技和快捷键来帮助我减少花费在重复编码上的时间。
现在不得不感谢 LLM 解放了这些烦人枯燥的工作,还有像原来我习惯使用 IDE 的调试模式来 debug 问题,现在一般直接让 LLM 生成大量的日志,调试完成后再回滚删除。还有类似于一次性的代码和脚本,原来需要纠结是写脚本快还是手动快,现在统一 LLM 生成,不再需要内耗和等待。
另外像部分的工程需求,不需要注意代码质量和复用的问题,完成任务就删除这些质量低劣但有效果的代码。下次有类似的需求再从头开始生成,反而比建立可复用的工程代码有效且好管理。
并且有时候也无需关心代码质量了,比如生成 demo 给客户演示,或者建立产品的新功能,有好的反馈和用户再考虑重构和质量,不好的情况直接删除即可。
这些都是在有 LLM 辅助之后发生的一些改变,我也不确定这种改变是否是好事,但是现在这个时代,确实要重新思考代码和产品,改变起来,总能获得更多的思考。
Vibe Coding
在讨论了这么多的 Context Coding 的经验和看法后,我们终于可以来谈谈 Vibe Coding 了。
在看完上面的内容后,你应该非常清楚,一个有经验的程序员在 LLM 的辅助下,编写出一份可读,具有可维护性,能够支撑未来需求变更的代码尚且如此不易,那么一个没有编程经验的人,想要完全通过 Vibe Coding 将一个产品上线和支撑未来的需求变更,现阶段还是一件非常困难的事情。
在短期内,Vibe Coding 会引入缺陷和安全漏洞,长期来看 Vibe Coding 会导致代码难以维护,技术债务堆积,整体系统的可理解性和稳定性大幅降低。
我看过最形象的一个解释是,让一个非程序员通过 Vibe Coding 来编写一个他们打算维护的大型项目,就相当于在没有先解释债务概念的情况下就给孩子一张信用卡。
在构建新功能的时候,就犹如挥舞这张小小的塑料卡,想买什么就买什么,想要编写什么新功能都能很快实现。只有当你需要维护它时,它才会变成债务。
如果你尝试通过 Vibe Coding 去修复另一个 Vibe Coding 导致的问题,这就像用另一张信用卡偿还信用卡债务一样。
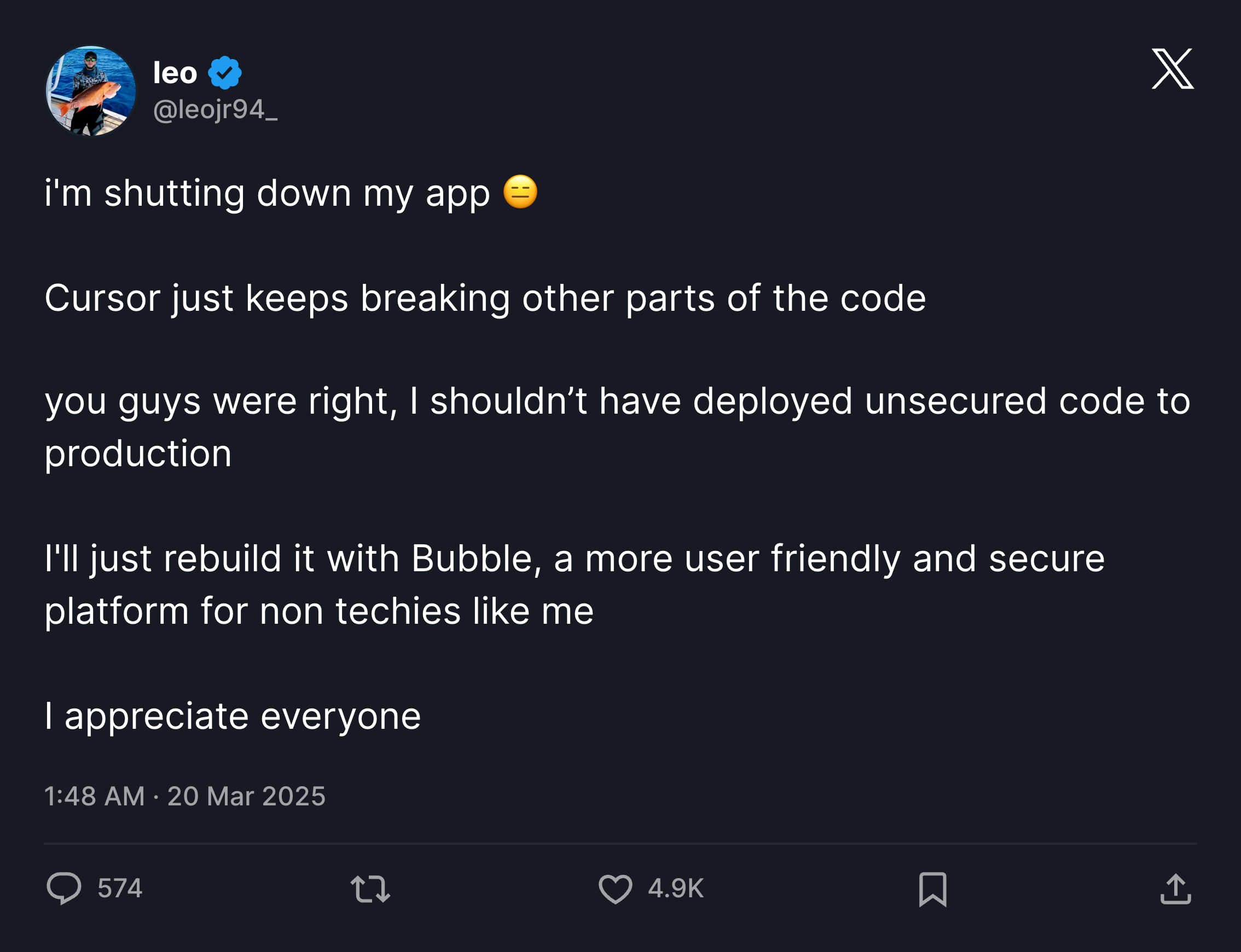
关于这件事情最好的注解应该就是在 X 上的这位 Leo 老哥的故事,他在今年 3 月 15 号的时候,发布了一个帖子,介绍他使用 Cursor 通过 Vibe Coding 的方式制作了一个产品,在全程没有参与手动编写代码的情况下,产品收获到了付费用户。
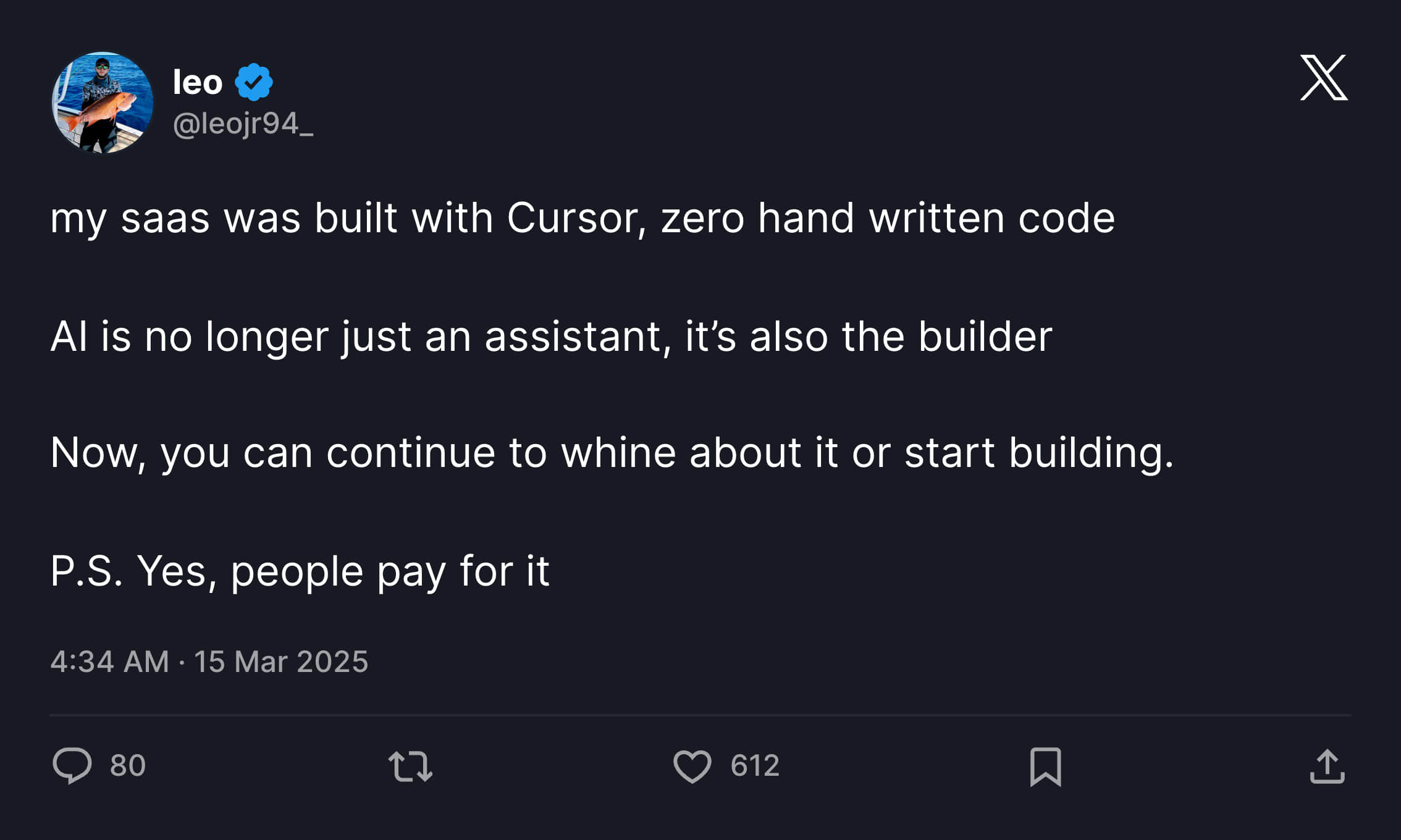
但仅仅过去了两天时间,事情就发生了一些变化,在上一篇帖子火了之后,有了攻击了他的产品,API 密钥的使用量达到了最大值,有人绕过了订阅,随意在数据库上创建一些东西。
因为 Leo 对技术不熟悉,每一个问题的解决都要比通过 Vibe Coding 构建功能要花费更长的时间。
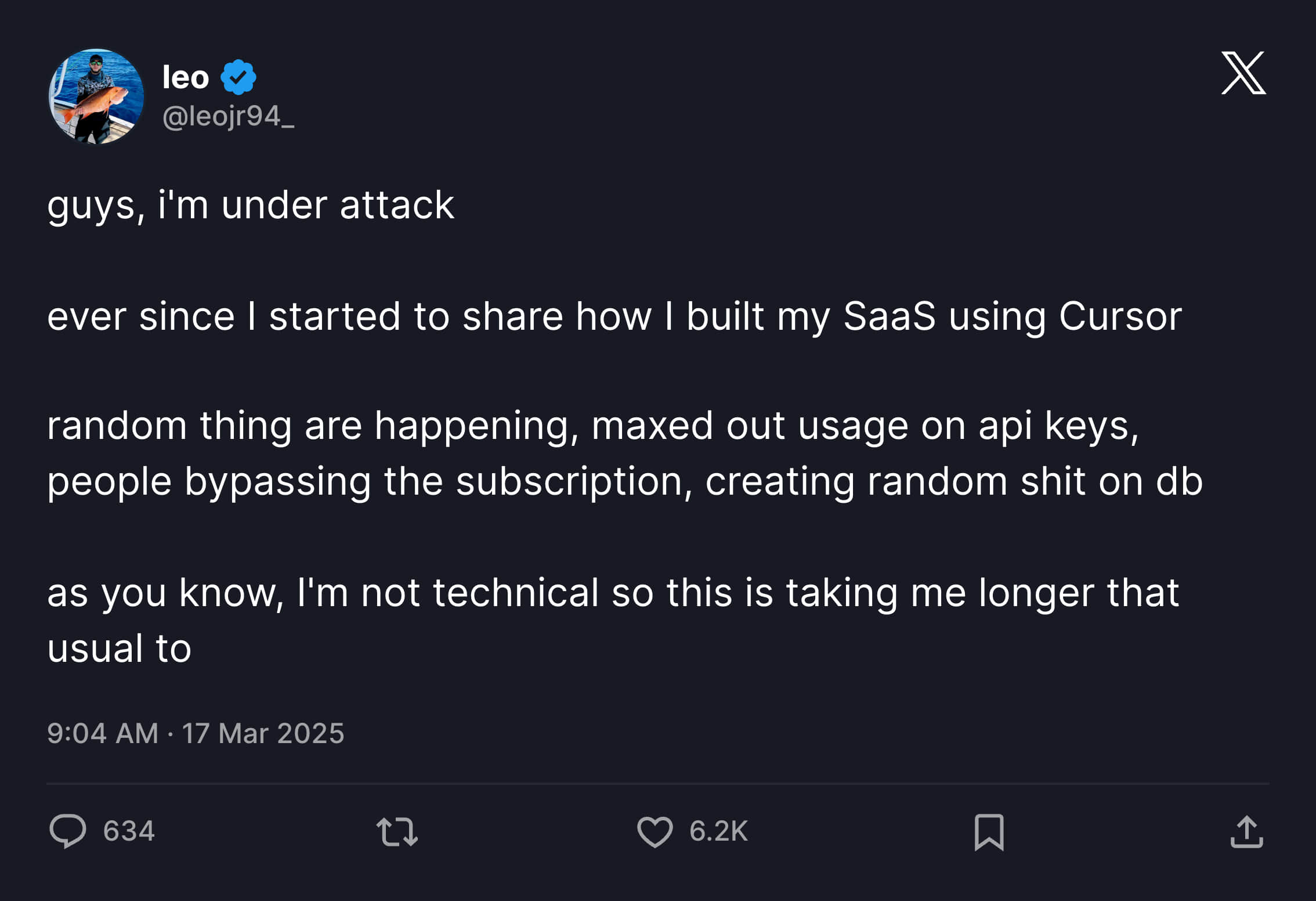
最后在 20 号的时候,Leo 不得不选择关掉他的产品,并且承认不应该将不安全的代码部署到生产环境。
相信看到这个故事的结局对于大部分程序员来说,应该都可以暂时长舒一口气,毕竟这意味着短期内没有失业的风险,自身的价值还在,但是长期呢?如何思考自己的职业生涯呢?
我对此一直持有悲观的态度,在 23 年的时候,我提到过在现代的社会分工里,少部分优秀的程序员改善代码质量和性能,分析解决技术难题,创造新的解决方案,设计系统结构和算法。但是大部分程序员的工作是翻译者,将人们的自然语言需求、业务逻辑转换成计算机能理解和执行的代码。
这就好比你吐槽老板不懂编程,把代码量当做工作量,老板却吐槽你不懂商业一样。从技术的角度出发,编程的本质是理论构建,是创意输出。
从商业的角度出发,资本将程序员细分为前端、后端、算法甚至更加细分的领域,好处是生产力的提升,细分领域的专注可以更好的技术创新,人才更好培养。而坏处是劳动异化,程序员不再是创意输出者,而是单个领域的生产者,生产过程中的一个螺丝钉,变成了一个失去独立性,方便随时替换的翻译工作者。
这也就意味着 Vibe Coding 还是从根本上革命了编程这个行业,随着 LLM 能力的增长,人们发现 LLM 也能充当这个翻译者后,Vibe Coding 会不断的蚕食和挤压程序员的生存空间。
从这个阶段开始,水平一般的程序员的数量会开始减少直到消亡,这个过程与其说是 AI 抢走了工作饭碗,不如说是被优秀的程序员抢走了工作饭碗,并且这两者的收入在这个阶段的差距也会不断加大。
时代的大潮浩浩荡荡,我并不想把未来想的过于悲观,也不想把事情讲的过于残酷,但在工业机器的轰鸣下,没有人会真的在意那些古法手工制作者的声音。在计算机出现之前,你也难以想象售票员、电话接线员是多么庞大的一个群体。
当然,我并不是说编程水平一般的程序员就找不到出路了,实际上在 AI 的加持下,一个编程水平一般的程序员,如果有不错的商业嗅觉,加上一定的营销能力,创造的商业价值远比在社会分工中当个螺丝钉要大的多。
过去可能需要很多人相互协作才能完成的工作,利用 AI 的杠杆可以大大的缩减工作时间和人员规模,未来的独立开发和小规模的团队协作一定会变得更加主流。
就像同样在今年 3 月,知名的独立开发者 Peter Levels 推出了完全 Vibe Coding 的产品:实时飞行模拟器MMO游戏。
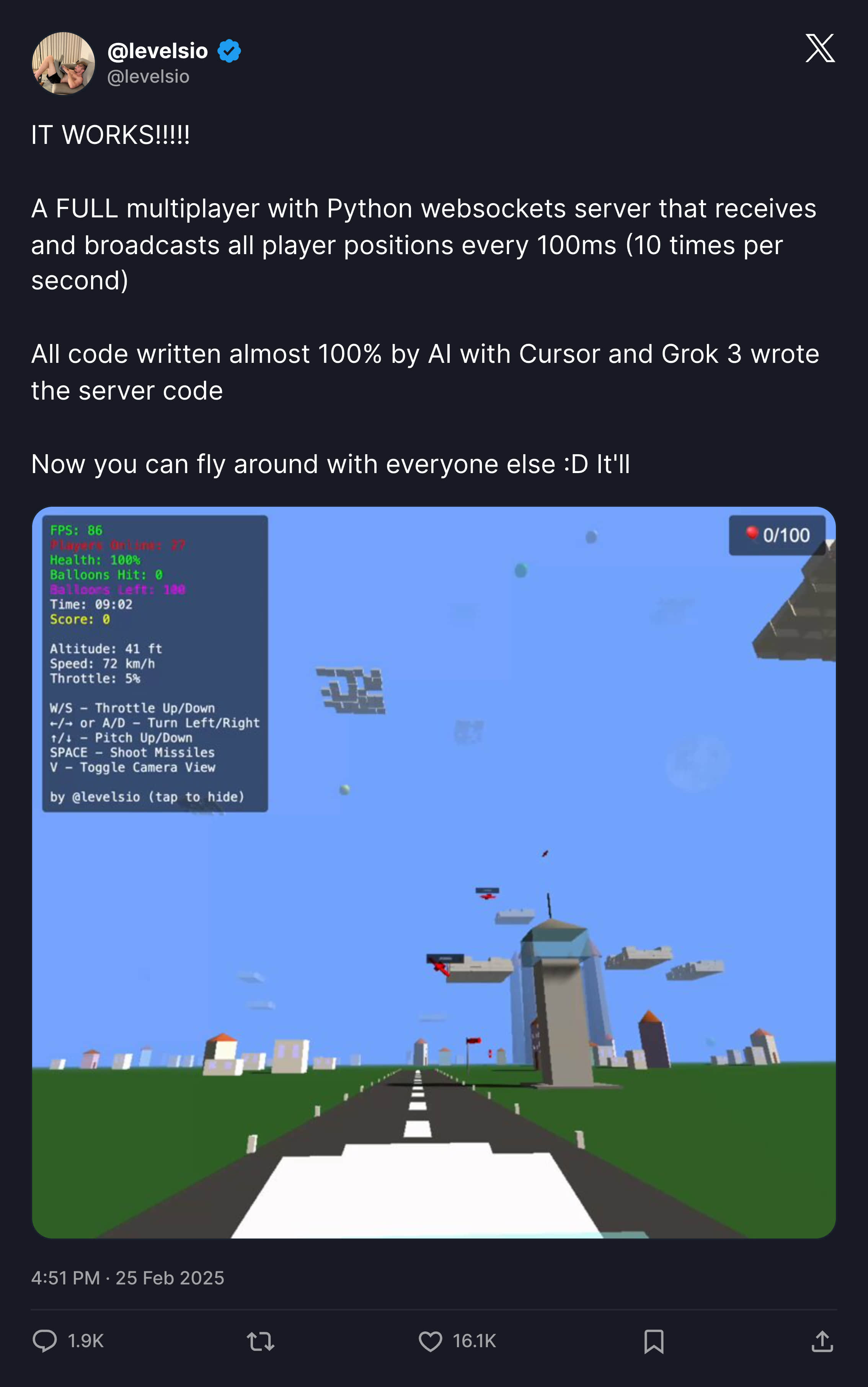
作者同样声明几乎所有代码 100% 由 AI + Cursor + Grok 3 实现,并且通过卖游戏内广告位赚取大量收入,从 0 到 100 万美元 ARR 仅用 17 天。
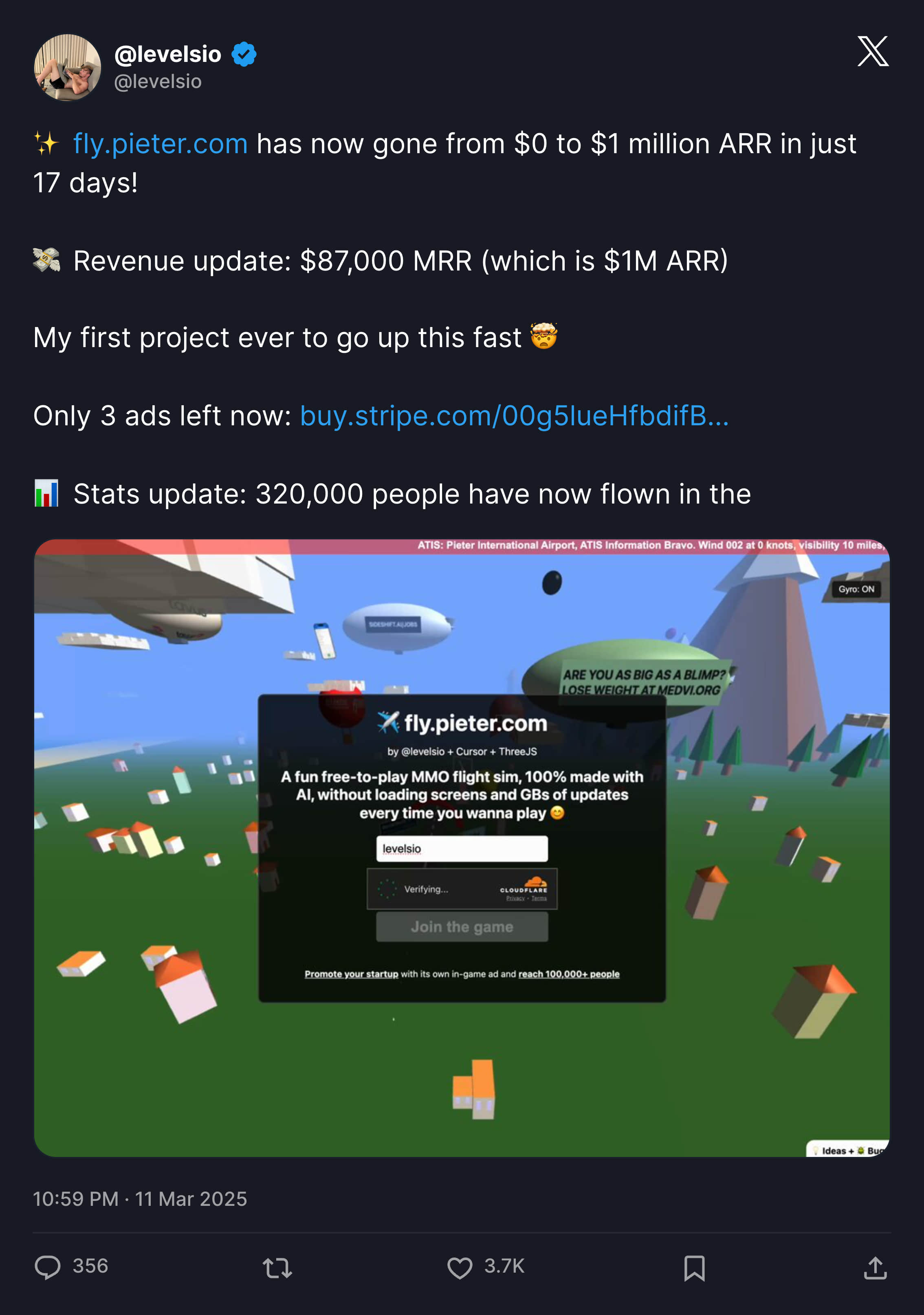
当然 Levels 在做这个项目之前,就已经是一个具有丰富编程经验的独立开发者,完全有随时接管项目的能力。并且这个产品的成功我觉得换个时间和创始人,也不一定能够如此成功,
举这个例子只是想要说明,职业和岗位可能会消失,但是需求和机会永远都会在。
在这个时代,唯一能解决这个问题和焦虑的,就是持续的学习和不断的实践,我个人相信程序员这个群体是最具有学习精神的群体,无论行业如何变化,具有持续学习能力的人永远是不可能被替代的。
希望我们都能在新的时代找到自己更喜欢的道路,本文写的仓促,包含了大量的个人观点,如果你有不同的观点,非常欢迎在下面进行评论。
References
- https://x.com/leojr94_/status/1901560276488511759
- https://x.com/leojr94_/status/1902537756674318347
- https://x.com/leojr94_/status/1900767509621674109
- https://x.com/karpathy/status/1959703967694545296
- https://cursor.com/security#codebase-indexing
- https://blog.val.town/vibe-code
- https://pages.cs.wisc.edu/~remzi/Naur.pdf
- https://x.com/levelsio/status/1899596115210891751
- https://x.com/levelsio/status/1894429987006288259