MCP 终极指南
2025年2月22日
过去快一年的时间没有更新 AI 相关的博客,一方面是在忙 side project,另外一方面也是因为 AI 技术虽然日新月异,但是 AI 应用层的开发并没有多少新的东西,大体还是2023年的博客讲的那三样,Prompt、RAG、Agent。
但是自从去年 11 月底 Claude(Anthropic) 主导发布了 MCP(Model Context Protocol 模型上下文协议) 后,AI 应用层的开发算是进入了新的时代。
不过关于 MCP 的解释和开发,目前似乎还没有太多的资料,所以笔者决定将自己的一些经验和思考整理成一篇文章,希望能够帮助到大家。
为什么 MCP 是一个突破
我们知道过去一年时间,AI 模型的发展非常迅速,从 GPT 4 到 Claude Sonnet 3.5 到 Deepseek R1,推理和幻觉都进步的非常明显。
新的 AI 应用也很多,但我们都能感受到的一点是,目前市场上的 AI 应用基本都是全新的服务,和我们原来常用的服务和系统并没有集成,换句话说,AI 模型和我们已有系统集成发展的很缓慢。
例如我们目前还不能同时通过某个 AI 应用来做到联网搜索、发送邮件、发布自己的博客等等,这些功能单个实现都不是很难,但是如果要全部集成到一个系统里面,就会变得遥不可及。
如果你还没有具体的感受,我们可以思考一下日常开发中,想象一下在 IDE 中,我们可以通过 IDE 的 AI 来完成下面这些工作。
- 询问 AI 来查询本地数据库已有的数据来辅助开发
- 询问 AI 搜索 Github Issue 来判断某问题是不是已知的bug
- 通过 AI 将某个 PR 的意见发送给同事的即时通讯软件(例如 Slack)来 Code Review
- 通过 AI 查询甚至修改当前 AWS、Azure 的配置来完成部署
以上谈到的这些功能通过 MCP 目前正在变为现实,大家可以关注 Cursor MCP 和 Windsurf MCP 获取更多的信息。可以试试用 Cursor MCP + browsertools 插件来体验一下在 Cursor 中自动获取 Chrome dev tools console log 的能力。
为什么 AI 集成已有服务的进展这么缓慢?这里面有很多的原因,一方面是企业级的数据很敏感,大多数企业都要很长的时间和流程来动。另一个方面是技术方面,我们缺少一个开放的、通用的、有共识的协议标准。
MCP 就是 Claude(Anthropic) 主导发布的一个开放的、通用的、有共识的协议标准,如果你是一个对 AI 模型熟悉的开发人员,想必对 Anthropic 这个公司不会陌生,他们发布了 Claude 3.5 Sonnet 的模型,到目前为止应该还是最强的编程 AI 模型(刚写完就发布了 3.7😅)。
这里还是要多提一句,这个协议的发布最好机会应该是属于 OpenAI 的,如果 OpenAI 刚发布 GPT 时就推动协议,相信大家都不会拒绝,但是 OpenAI 变成了 CloseAI,只发布了一个封闭的 GPTs,这种需要主导和共识的标准协议一般很难社区自发形成,一般由行业巨头来主导。
Claude 发布了 MCP 后,官方的 Claude Desktop 就开放了 MCP 功能,并且推动了开源组织 Model Context Protocol,由不同的公司和社区进行参与,例如下面就列举了一些由不同组织发布 MCP 服务器的例子。
MCP 官方集成教学:
- Git - Git 读取、操作、搜索。
- GitHub - Repo 管理、文件操作和 GitHub API 集成。
- Google Maps - 集成 Google Map 获取位置信息。
- PostgreSQL - 只读数据库查询。
- Slack - Slack 消息发送和查询。
🎖️ 第三方平台官方支持 MCP 的例子
由第三方平台构建的 MCP 服务器。
🌎 社区 MCP 服务器
下面是一些由开源社区开发和维护的 MCP 服务器。
- AWS - 用 LLM 操作 AWS 资源。
- Atlassian - 与 Confluence 和 Jira 进行交互,包括搜索/查询 Confluence 空间/页面,访问 Jira Issue 和项目。
- Google Calendar - 与 Google 日历集成,日程安排,查找时间,并添加/删除事件。
- Kubernetes - 连接到 Kubernetes 集群并管理 pods、deployments 和 services。
- X (Twitter) - 与 Twitter API 交互。发布推文并通过查询搜索推文。
- YouTube - 与 YouTube API 集成,视频管理、短视频创作等。
为什么是 MCP?
看到这里你可能有一个问题,在 23 年 OpenAI 发布 GPT function calling 的时候,不是也是可以实现类似的功能吗?我们之前博客介绍的 AI Agent,不就是用来集成不同的服务吗?为什么又出现了 MCP。
function calling、AI Agent、MCP 这三者之间有什么区别?
Function Calling
- Function Calling 指的是 AI 模型根据上下文自动执行函数的机制。
- Function Calling 充当了 AI 模型与外部系统之间的桥梁,不同的模型有不同的 Function Calling 实现,代码集成的方式也不一样。由不同的 AI 模型平台来定义和实现。
如果我们使用 Function Calling,那么需要通过代码给 LLM 提供一组 functions,并且提供清晰的函数描述、函数输入和输出,那么 LLM 就可以根据清晰的结构化数据进行推理,执行函数。
Function Calling 的缺点在于处理不好多轮对话和复杂需求,适合边界清晰、描述明确的任务。如果需要处理很多的任务,那么 Function Calling 的代码比较难维护。
Model Context Protocol (MCP)
- MCP 是一个标准协议,如同电子设备的 Type C 协议(可以充电也可以传输数据),使 AI 模型能够与不同的 API 和数据源无缝交互。
- MCP 旨在替换碎片化的 Agent 代码集成,从而使 AI 系统更可靠,更有效。通过建立通用标准,服务商可以基于协议来推出它们自己服务的 AI 能力,从而支持开发者更快的构建更强大的 AI 应用。开发者也不需要重复造轮子,通过开源项目可以建立强大的 AI Agent 生态。
- MCP 可以在不同的应用/服务之间保持上下文,从而增强整体自主执行任务的能力。
可以理解为 MCP 是将不同任务进行分层处理,每一层都提供特定的能力、描述和限制。而 MCP Client 端根据不同的任务判断,选择是否需要调用某个能力,然后通过每层的输入和输出,构建一个可以处理复杂、多步对话和统一上下文的 Agent。
AI Agent
- AI Agent 是一个智能系统,它可以自主运行以实现特定目标。传统的 AI 聊天仅提供建议或者需要手动执行任务,AI Agent 则可以分析具体情况,做出决策,并自行采取行动。
- AI Agent 可以利用 MCP 提供的功能描述来理解更多的上下文,并在各种平台/服务自动执行任务。
思考
为什么 Claude 推出 MCP 后会被广泛接受呢?其实在过去的一年中我个人也参与了几个小的 AI 项目的开发工作,在开发的过程中,将 AI 模型集成现有的系统或者第三方系统确实挺麻烦。
虽然市面上有一些框架支持 Agent 开发,例如 LangChain Tools, LlamaIndex 或者是 Vercel AI SDK。
LangChain 和 LlamaIndex 虽然都是开源项目,但是整体发展还是挺混乱的,首先是代码的抽象层次太高了,想要推广的都是让开发人员几行代码就完成某某 AI 功能,这在 Demo 阶段是挺好用的,但是在实际开发中,只要业务一旦开始复杂,糟糕的代码设计带来了非常糟糕的编程体验。还有就是这几个项目都太想商业化了,忽略了整体生态的建设。
还有一个就是 Vercel AI SDK,尽管个人觉得 Vercel AI SDK 代码抽象的比较好,但是也只是对于前端 UI 结合和部分 AI 功能的封装还不错,最大的问题是和 Nextjs 绑定太深了,对其它的框架和语言支持度不够。
所以 Claude 推动 MCP 可以说是一个很好的时机,首先是 Claude Sonnet 3.5 在开发人员心中有较高的地位,而 MCP 又是一个开放的标准,所以很多公司和社区都愿意参与进来,希望 Claude 能够一直保持一个良好的开放生态。
MCP 对于社区生态的好处主要是下面两点:
- 开放标准给服务商,服务商可以针对 MCP 开放自己的 API 和部分能力。
- 不需要重复造轮子,开发者可以用已有的开源 MCP 服务来增强自己的 Agent。
MCP 如何工作
那我们来介绍一下 MCP 的工作原理。首先我们看一下官方的 MCP 架构图。
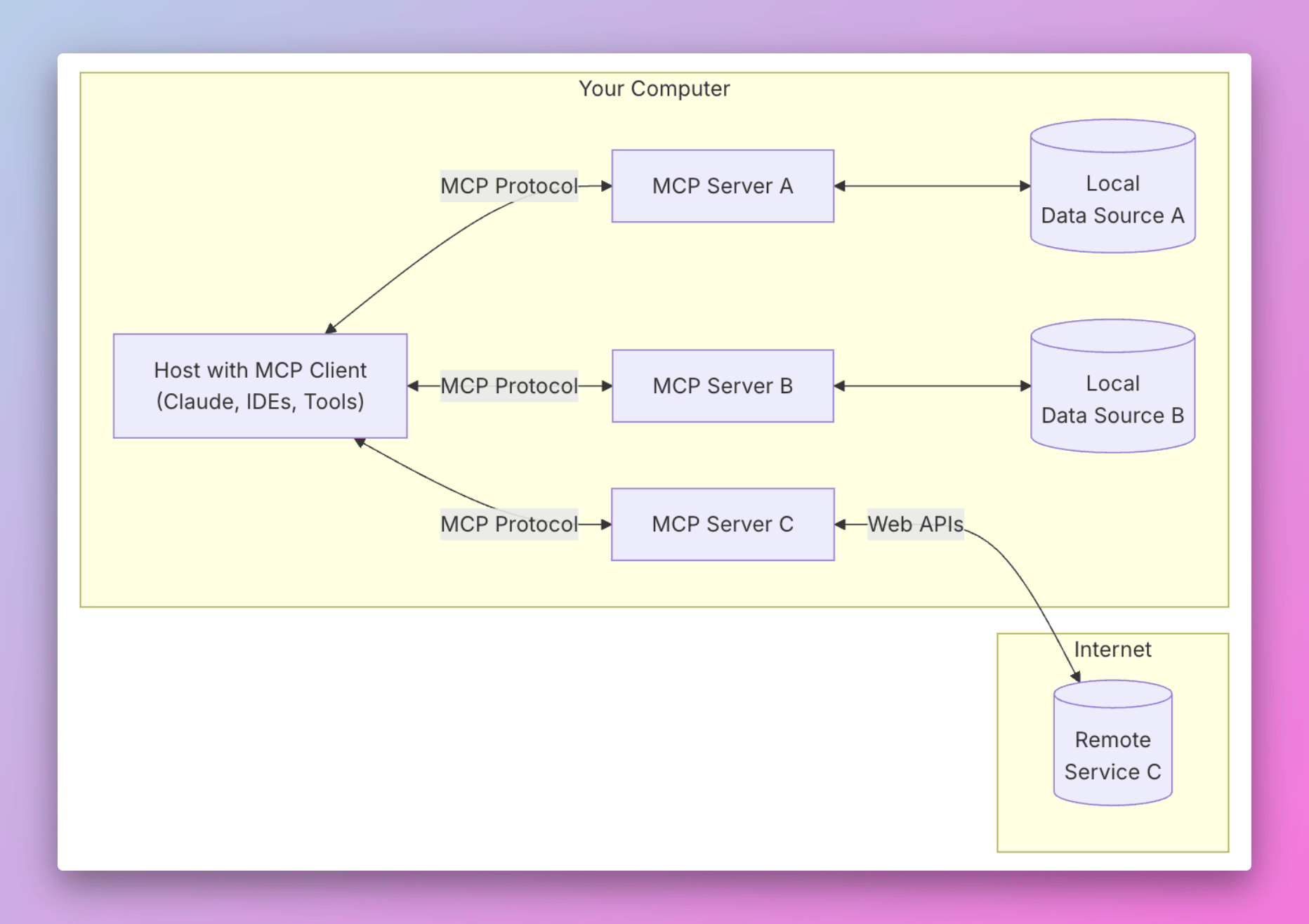
总共分为了下面五个部分:
- MCP Hosts: Hosts 是指 LLM 启动连接的应用程序,像 Cursor, Claude Desktop、Cline 这样的应用程序。
- MCP Clients: 客户端是用来在 Hosts 应用程序内维护与 Server 之间 1:1 连接。
- MCP Servers: 通过标准化的协议,为 Client 端提供上下文、工具和提示。
- Local Data Sources: 本地的文件、数据库和 API。
- Remote Services: 外部的文件、数据库和 API。
整个 MCP 协议核心的在于 Server,因为 Host 和 Client 相信熟悉计算机网络的都不会陌生,非常好理解,但是 Server 如何理解呢?
看看 Cursor 的 AI Agent 发展过程,我们会发现整个 AI 自动化的过程发展会是从 Chat 到 Composer 再进化到完整的 AI Agent。
AI Chat 只是提供建议,如何将 AI 的 response 转化为行为和最终的结果,全部依靠人类,例如手动复制粘贴,或者进行某些修改。
AI Composer 是可以自动修改代码,但是需要人类参与和确认,并且无法做到除了修改代码之外的其它操作。
AI Agent 是一个完全的自动化程序,未来完全可以做到自动读取 Figma 的图片,自动生产代码,自动读取日志,自动调试代码,自动 push 代码到 GitHub。
而 MCP Server 就是为了实现 AI Agent 的自动化而存在的,它是一个中间层,告诉 AI Agent 目前存在哪些服务,哪些 API,哪些数据源,AI Agent 可以根据 Server 提供的信息来决定是否调用某个服务,然后通过 Function Calling 来执行函数。
MCP Server 的工作原理
我们先来看一个简单的例子,假设我们想让 AI Agent 完成自动搜索 GitHub Repository,接着搜索 Issue,然后再判断是否是一个已知的 bug,最后决定是否需要提交一个新的 Issue 的功能。
那么我们就需要创建一个 Github MCP Server,这个 Server 需要提供查找 Repository、搜索 Issues 和创建 Issue 三种能力。
我们直接来看看代码:
const server = new Server(
{
name: "github-mcp-server",
version: VERSION,
},
{
capabilities: {
tools: {},
},
}
);
server.setRequestHandler(ListToolsRequestSchema, async () => {
return {
tools: [
{
name: "search_repositories",
description: "Search for GitHub repositories",
inputSchema: zodToJsonSchema(repository.SearchRepositoriesSchema),
},
{
name: "create_issue",
description: "Create a new issue in a GitHub repository",
inputSchema: zodToJsonSchema(issues.CreateIssueSchema),
},
{
name: "search_issues",
description: "Search for issues and pull requests across GitHub repositories",
inputSchema: zodToJsonSchema(search.SearchIssuesSchema),
}
],
};
});
server.setRequestHandler(CallToolRequestSchema, async (request) => {
try {
if (!request.params.arguments) {
throw new Error("Arguments are required");
}
switch (request.params.name) {
case "search_repositories": {
const args = repository.SearchRepositoriesSchema.parse(request.params.arguments);
const results = await repository.searchRepositories(
args.query,
args.page,
args.perPage
);
return {
content: [{ type: "text", text: JSON.stringify(results, null, 2) }],
};
}
case "create_issue": {
const args = issues.CreateIssueSchema.parse(request.params.arguments);
const { owner, repo, ...options } = args;
const issue = await issues.createIssue(owner, repo, options);
return {
content: [{ type: "text", text: JSON.stringify(issue, null, 2) }],
};
}
case "search_issues": {
const args = search.SearchIssuesSchema.parse(request.params.arguments);
const results = await search.searchIssues(args);
return {
content: [{ type: "text", text: JSON.stringify(results, null, 2) }],
};
}
default:
throw new Error(`Unknown tool: ${request.params.name}`);
}
} catch (error) {}
});
async function runServer() {
const transport = new StdioServerTransport();
await server.connect(transport);
console.error("GitHub MCP Server running on stdio");
}
runServer().catch((error) => {
console.error("Fatal error in main():", error);
process.exit(1);
});上面的代码中,我们通过 server.setRequestHandler 来告诉 Client 端我们提供了哪些能力,通过 description 字段来描述这个能力的作用,通过 inputSchema 来描述完成这个能力需要的输入参数。
我们再来看看具体的实现代码:
export const SearchOptions = z.object({
q: z.string(),
order: z.enum(["asc", "desc"]).optional(),
page: z.number().min(1).optional(),
per_page: z.number().min(1).max(100).optional(),
});
export const SearchIssuesOptions = SearchOptions.extend({
sort: z.enum([
"comments",
...
]).optional(),
});
export async function searchUsers(params: z.infer<typeof SearchUsersSchema>) {
return githubRequest(buildUrl("https://api.github.com/search/users", params));
}
export const SearchRepositoriesSchema = z.object({
query: z.string().describe("Search query (see GitHub search syntax)"),
page: z.number().optional().describe("Page number for pagination (default: 1)"),
perPage: z.number().optional().describe("Number of results per page (default: 30, max: 100)"),
});
export async function searchRepositories(
query: string,
page: number = 1,
perPage: number = 30
) {
const url = new URL("https://api.github.com/search/repositories");
url.searchParams.append("q", query);
url.searchParams.append("page", page.toString());
url.searchParams.append("per_page", perPage.toString());
const response = await githubRequest(url.toString());
return GitHubSearchResponseSchema.parse(response);
}可以很清晰的看到,我们最终实现是通过了 https://api.github.com 的 API 来实现和 Github 交互的,我们通过 githubRequest 函数来调用 GitHub 的 API,最后返回结果。
在调用 Github 官方的 API 之前,MCP 的主要工作是描述 Server 提供了哪些能力(给 LLM 提供),需要哪些参数(参数具体的功能是什么),最后返回的结果是什么。
所以 MCP Server 并不是一个新颖的、高深的东西,它只是一个具有共识的协议。
如果我们想要实现一个更强大的 AI Agent,例如我们想让 AI Agent 自动的根据本地错误日志,自动搜索相关的 GitHub Repository,然后搜索 Issue,最后将结果发送到 Slack。
那么我们可能需要创建三个不同的 MCP Server,一个是 Local Log Server,用来查询本地日志;一个是 GitHub Server,用来搜索 Issue;还有一个是 Slack Server,用来发送消息。
AI Agent 在用户输入 我需要查询本地错误日志,将相关的 Issue 发送到 Slack 指令后,自行判断需要调用哪些 MCP Server,并决定调用顺序,最终根据不同 MCP Server 的返回结果来决定是否需要调用下一个 Server,以此来完成整个任务。
如何使用 MCP
如果你还没有尝试过如何使用 MCP 的话,我们可以考虑用 Cursor(本人只尝试过 Cursor),Claude Desktop 或者 Cline 来体验一下。
当然,我们并不需要自己开发 MCP Servers,MCP 的好处就是通用、标准,所以开发者并不需要重复造轮子(但是学习可以重复造轮子)。
首先推荐的是官方组织的一些 Server:官方的 MCP Server 列表。
目前社区的 MCP Server 还是比较混乱,有很多缺少教程和文档,很多的代码功能也有问题,我们可以自行尝试一下 Cursor Directory 的一些例子,具体的配置和实战笔者就不细讲了,大家可以参考官方文档。
MCP 的一些资源
下面是个人推荐的一些 MCP 的资源,大家可以参考一下。
MCP 官方资源
社区的 MCP Server 的列表
写在最后
本篇文章写的比较仓促,如果有错误再所难免,欢迎各位大佬指正。
最后本篇文章可以转载,但是请注明出处,会在 X/Twitter,小红书, 微信公众号 同步发布,欢迎各位大佬关注一波。
{kind=link}
博客同步发布到 NextDevKit Blog Model Context Protocol。
References
- https://guangzhengli.com/blog/zh/gpt-embeddings/
- https://docs.cursor.com/context/model-context-protocol
- https://www.youtube.com/watch?v=Y_kaQmhGmZk
- https://browsertools.agentdesk.ai/installation
- https://github.com/modelcontextprotocol
- https://github.com/grafana/mcp-grafana
- https://github.com/JetBrains/mcp-jetbrains
- https://github.com/stripe/agent-toolkit
- https://github.com/rishikavikondala/mcp-server-aws
- https://github.com/sooperset/mcp-atlassian
- https://github.com/v-3/google-calendar
- https://github.com/Flux159/mcp-server-kubernetes
- https://github.com/EnesCinr/twitter-mcp
- https://github.com/ZubeidHendricks/youtube-mcp-server
- https://www.langchain.com/
- https://docs.llamaindex.ai/en/stable/
- https://sdk.vercel.ai/docs/introduction
- https://modelcontextprotocol.io/introduction
- https://github.com/cline/cline
- https://github.com/modelcontextprotocol/servers
- https://www.anthropic.com/news/model-context-protocol
- https://cursor.directory
- https://www.pulsemcp.com/
- https://glama.ai/mcp/servers